○ 내 블로그 포스팅 제목 크롤링하기
1) 1단계 : 페이지 1에 있는 내용 전체 크롤링 (https://binscode.tistory.com/category)

import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test01_crawling {
public static void main(String[] args) {
try {
String URL="https://binscode.tistory.com/category";
Document doc=Jsoup.connect(URL).get();
System.out.println(doc.toString());
}catch (Exception e) {
System.out.println("크롤링 실패: " + e);
}//try end
}//main() end
}//class end
2) 2단계 : 모든 페이지 내용 크롤링
- 총 107개 포스팅, 한 페이지에 8개씩 포스팅 노출되므로 총 페이지 14
- 크롤링할 URL : https://binscode.tistory.com/category?page=1 ~ page=14

import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test02_crawling {
public static void main(String[] args) {
try {
String URL="https://binscode.tistory.com/category";
String params= "";
for(int page=1; page<=14; page++) {
params = "?page=" + page; // ?뒤의 문자열을 구성
Document doc=Jsoup.connect(URL+params).get();
System.out.println(doc.toString());
}//for end
} catch (Exception e) {
System.out.println("크롤링 실패: " + e);
}//try end
}//main() end
}//class end
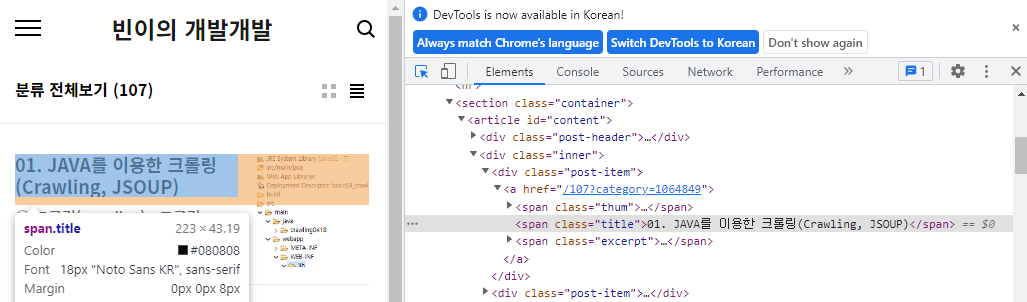
3) 3단계 : 모든 페이지 내용 중 제목만 크롤링
- 크롬 개발자도구(F12)를 이용해 포스팅 제목의 요소 분석
- class="title" 요소만 크롤링하기 : Element, Elements 클래스 이용
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test03_crawling {
public static void main(String[] args) {
try {
String URL="https://binscode.tistory.com/category";
String params= "";
for(int page=1; page<=14; page++) {
params = "?page=" + page;
Document doc=Jsoup.connect(URL+params).get();
Elements elements=doc.select(".title"); //class="title"
for(Element element : elements) {
System.out.println(element.text()); //107개 제목 출력
}//for end
}//for end
} catch (Exception e) {
System.out.println("크롤링 실패: " + e);
}//try end
}//main() end
}//class end
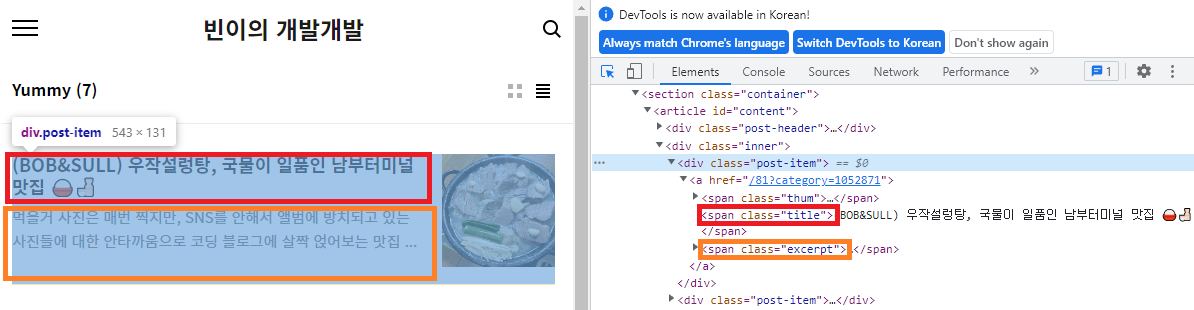
+) 어떠한 요소 안에 있는 요소들 중에서 특정 요소만 제거하고 싶을 때
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test04_crawling {
public static void main(String[] args) {
try {
String URL="https://binscode.tistory.com/category/Yummy";
Document doc=Jsoup.connect(URL).get();
Elements elements=doc.select(".post-item");
elements.select(".excerpt").remove(); //class=excerpt 제거
for(Element element : elements) {
System.out.println(element.text());
}//for end
} catch (Exception e) {
System.out.println("크롤링 실패: " + e);
}//try end
}//main() end
}//class end

'Backend > JAVA_Crawling' 카테고리의 다른 글
| 03. JAVA를 이용한 네이버 영화 평점 크롤링 (AJAX가 적용된 사이트, 크롤링 결과 파일로 저장하기) (0) | 2022.06.13 |
|---|---|
| 01. JAVA를 이용한 크롤링(Crawling, JSOUP) (0) | 2022.06.10 |


댓글